
My name is Alex Bazooka, and I am a senior SEO expert with a lot of experience in both SEO and AI optimization. During my time working on enterprise sites, I’ve seen firsthand how the SEO landscape has changed in big ways. We’ve been optimizing for Googlebot and Bingbot for years, but a new wave of AI crawlers is using up a lot of server resources without adding much to your organic visibility.
The data tells a stark story: AI crawlers can account for 5-10% of total crawler traffic on many sites, yet they rarely translate to improved rankings or traffic. Meanwhile, a genuine crawl budget crisis may be developing as legitimate search engine crawlers run out of resources, leaving most SEOs ill-prepared to handle it.
Understanding Modern Crawl Budget Dynamics
The way Google used to define crawl budget is no longer the same. In 2025, we have a complex ecosystem where AI training crawlers, LLM data collectors, and experimental bots all fight with search engines for your server resources.
The New Crawler Landscape
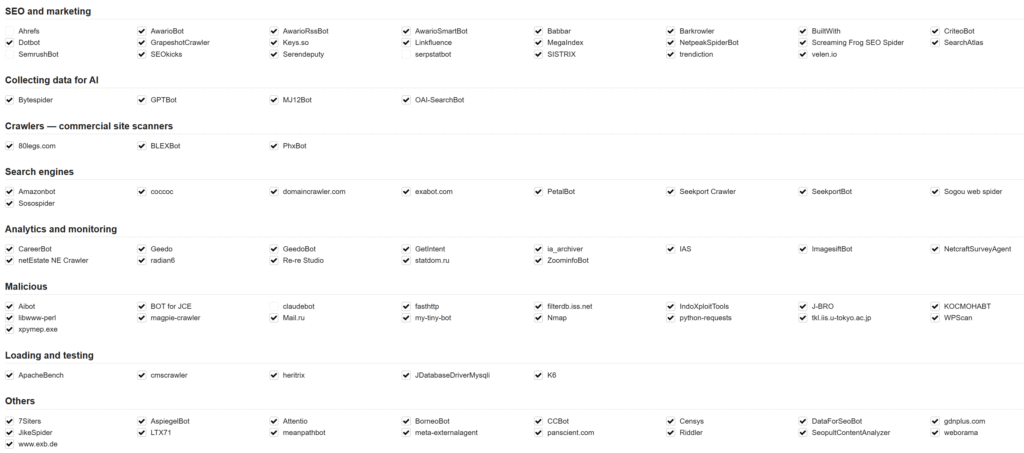
The main goal of traditional crawl budget optimization was to make Googlebot work better. Today’s world is more complicated:
Search Engine Crawlers (Priority: Critical)
- Googlebot variants (desktop, mobile, images, news)
- Bingbot and emerging search engines
- Specialized crawlers (Google-InspectionTool, Google-Read-Aloud)
AI Training Crawlers (Priority: Evaluate)
- OpenAI’s GPTBot and ChatGPT-User
- Anthropic’s Claude-Web
- Meta’s FacebookBot (AI training variant)
- Numerous academic and research crawlers
Unknown/Aggressive Crawlers (Priority: Monitor/Block)
- Undisclosed AI data collectors
- SEO tools masquerade as legitimate crawlers.
- Malicious scrapers use AI crawler user agents.
The challenge isn’t just volume—it’s resource allocation. Every request served to a non-productive crawler is a missed opportunity for search engines to discover and index your valuable content.
Server Log Analysis for Crawler Intelligence
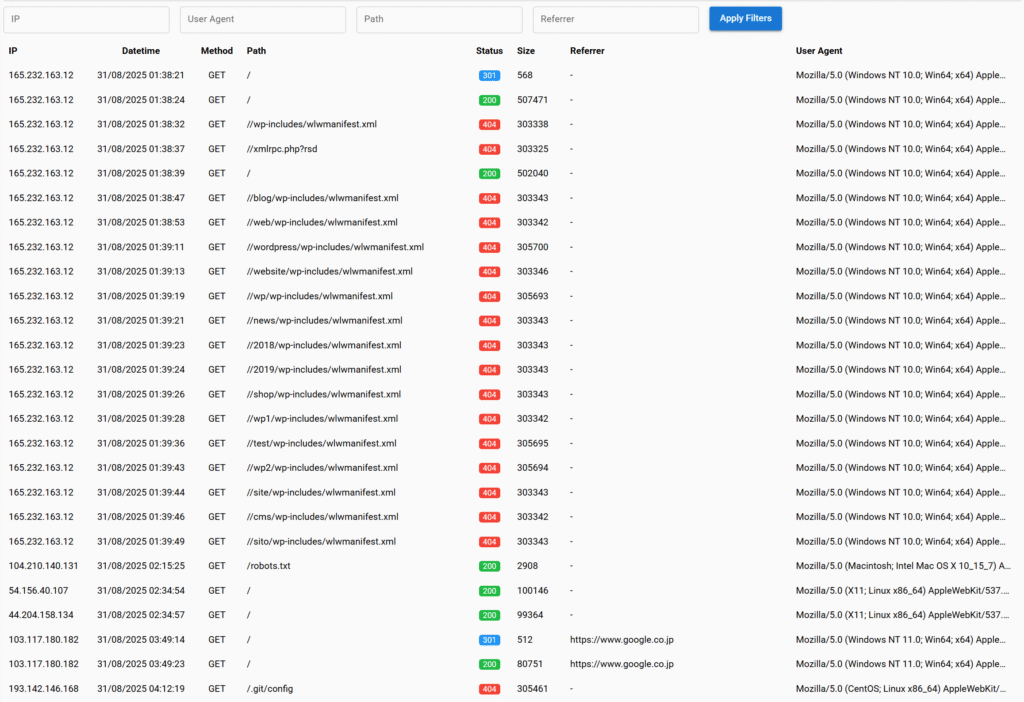
When I check a site’s crawler problems, I always start by looking at the raw server logs. A lot of SEOs only use Google Analytics or Search Console data, but those tools will never give you the full picture of what’s going on with your crawler traffic.
Raw server logs remain your most reliable source of truth for crawler behavior. Analytics platforms often filter or misclassify crawler traffic, leaving you blind to the actual resource consumption that’s potentially choking your site’s performance.
Key Metrics to Track
When analyzing crawler behavior, focus on these critical indicators:
| Name of Metrics | Description of |
|---|---|
| Request Volume by User Agent | Keep an eye on the daily requests, which are sorted by the type of crawler. Look for any strange spikes or patterns that don’t match up with when the content was published. |
| Resource Intensity Patterns | Some requests are more important than others. Keep track of which crawlers keep asking for pages with many resources, big files, or complex database queries. |
| Response Code Distribution | If certain crawlers have high 4xx rates, it could mean that there are problems with the configuration or that they are aggressively crawling URLs that don’t exist, which wastes crawl budget. |
| Crawl Depth and Path Analysis | Find out which parts of the site are most important to different crawlers. AI crawlers and search engine crawlers don’t always behave the same way. For example, AI crawlers might focus a lot on user-generated content or certain types of content. |
Practical Log Analysis Implementation
Here’s a server log query structure I use for initial crawler assessment:
awk '$9 == "200" {crawlers[$14]++; bytes[$14]+=$10} END {for (c in crawlers) print c, crawlers[c], bytes[c]}' access.log | sort -k2 -nrThis provides request counts and byte consumption by user agent, giving you immediate insight into which crawlers are consuming the most resources.
For deeper analysis, segment by times to identify crawling patterns:
awk '{print $4, $14, $9, $10}' access.log | grep "GPTBot\|Claude-Web\|ChatGPT" | awk '{date=substr($1,2,11); crawler=$2; print date, crawler}'Strategic Robots.txt Directives for AI Crawler Control
The llms.txt Reality Check
Before I dive you into advanced robots.txt strategies, let’s address the elephant in the room: llms.txt. This proposed standard, designed to provide AI crawlers with explicit permissions and guidelines, sounds promising in theory. In practice? It’s largely ineffective right now.
After testing llms.txt implementation across multiple enterprise sites, the compliance rate among AI crawlers is disappointingly low. Most AI crawlers either don’t look at llms.txt at all or don’t read it the same way every time. The specification is still changing, and it won’t be a practical solution until major AI companies start using it widely.
My recommendation: implement llms.txt if you want to be forward-thinking, but don’t rely on it for actual crawler control. Traditional robots.txt combined with server-level controls remains your most reliable approach.
Although the robots.txt file continues to be your primary defense, the compliance of AI crawlers varies significantly. Based on testing across multiple enterprise sites, here’s what actually works:
Effective AI Crawler Blocking Patterns
Comprehensive AI Crawler List
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: FacebookBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /Selective Content Protection For sites that want to allow some AI crawling while protecting sensitive areas:
User-agent: GPTBot
Disallow: /admin/
Disallow: /user/
Disallow: /checkout/
Disallow: /search?
Crawl-delay: 10
User-agent: Claude-Web
Disallow: /premium/
Disallow: /subscriber/
Crawl-delay: 15Advanced Robots.txt Strategies
Dynamic Content Exclusion Use robots.txt to exclude dynamically generated content that doesn’t add SEO value but consumes significant resources:
User-agent: *
Disallow: /*?utm_
Disallow: /*sessionid=
Disallow: /print/
Disallow: /pdf-export/Time-Based Crawling Controls Implement crawl-delay directives strategically. While search engines often ignore these, many AI crawlers respect them:
User-agent: *
Crawl-delay: 1
User-agent: GPTBot
Crawl-delay: 30
User-agent: Claude-Web
Crawl-delay: 30Bot Fingerprinting and Advanced Detection
Robots.txt compliance is voluntary. Sophisticated crawlers often ignore these directives or use misleading user agents. This is where bot fingerprinting becomes critical.
Behavioral Analysis Patterns
Request Frequency Analysis Legitimate search engine crawlers typically follow predictable patterns with natural delays between requests. AI training crawlers often show more aggressive, machine-like patterns:
- Consistent inter-request timing (exactly X seconds between requests)
- High request rates without regard for server response times
- Simultaneous requests from multiple IP ranges
HTTP Header Fingerprinting Analyze request headers for inconsistencies:
Accept Headers: Search engine crawlers typically include specific Accept headers. Generic or missing Accept headers often indicate non-browser crawlers.
Accept-Encoding: Legitimate crawlers usually support compression. Missing compression support can indicate basic scrapers.
Connection Headers: Persistent connection patterns differ between legitimate crawlers and scrapers.
IP Range Analysis
Maintain updated IP ranges for major crawlers and implement allowlisting for critical crawlers:
Google Crawler Verification
bash
host 66.249.66.1
# Should resolve to *.googlebot.com
host crawl-66-249-66-1.googlebot.com
# Should resolve back to the original IPSuspicious IP Pattern Detection Look for crawlers claiming to be legitimate while operating from non-matching IP ranges:
- Cloud hosting providers (AWS, GCP, Azure) for claimed search engine crawlers
- Residential IP proxies for enterprise AI crawlers
- Geographic distribution that doesn’t match claimed crawler origin
WAF Rules for Aggressive Crawler Management
Web Application Firewalls provide the most granular control over crawler access, allowing you to implement sophisticated rules that go beyond simple blocking.
Rate Limiting Strategies
Tiered Rate Limiting Implement different rate limits based on crawler importance:
# Critical crawlers (Googlebot, Bingbot)
Rate limit: 60 requests/minute
# Known AI crawlers (with permission)
Rate limit: 10 requests/minute
# Unknown crawlers
Rate limit: 5 requests/minute
# Suspected scrapers
Rate limit: 1 request/minuteDynamic Rate Adjustment Adjust rate limits based on server load and crawler behavior:
- Reduce limits during peak traffic hours
- Increase limits for well-behaved crawlers
- Implement progressive penalties for rule violations
Advanced WAF Rule Configurations
JavaScript Challenge Implementation Force suspected non-legitimate crawlers through JavaScript challenges:
javascript
// CloudFlare Workers example
if (request.headers.get('user-agent').includes('unknown-crawler')) {
return new Response('Challenge required', {
status: 503,
headers: { 'Retry-After': '300' }
});
}Geographic Restriction Rules Implement geographic blocks for crawlers that don’t match their claimed origin:
# Block GPTBot claims from outside OpenAI's known IP ranges
if ($http_user_agent ~* "GPTBot") {
if ($remote_addr !~ "^(20\.15\.|40\.83\.|52\.230\.)") {
return 403;
}
}Crawl Rate Limiter Implementation
Server-level crawl rate limiting provides the most reliable control over crawler resource consumption, regardless of robots.txt compliance.
Nginx-Based Rate Limiting
Basic Crawler Rate Limiting
nginx
http {
# Define rate limiting zones
limit_req_zone $binary_remote_addr zone=crawler:10m rate=1r/s;
limit_req_zone $http_user_agent zone=ai_crawlers:10m rate=1r/10s;
# Map user agents to zones
map $http_user_agent $crawler_zone {
~*googlebot crawler;
~*bingbot crawler;
~*gptbot ai_crawlers;
~*claude-web ai_crawlers;
default crawler;
}
}
server {
location / {
limit_req zone=$crawler_zone burst=5 nodelay;
# Your normal configuration
}
}Advanced Multi-Tier Rate Limiting
nginx
# Separate zones for different crawler priorities
limit_req_zone $binary_remote_addr zone=priority_crawlers:10m rate=10r/s;
limit_req_zone $binary_remote_addr zone=ai_crawlers:10m rate=1r/s;
limit_req_zone $binary_remote_addr zone=unknown_crawlers:10m rate=1r/30s;
map $http_user_agent $rate_limit_zone {
~*googlebot priority_crawlers;
~*bingbot priority_crawlers;
~*gptbot ai_crawlers;
~*claude-web ai_crawlers;
~*anthropic ai_crawlers;
default unknown_crawlers;
}Apache-Based Solutions
mod_rewrite Rate Limiting
apache
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} ^.*GPTBot.*$ [NC]
RewriteRule ^.*$ - [E=rate_limit:1]
RewriteCond %{ENV:rate_limit} =1
RewriteCond %{REQUEST_URI} !^/robots\.txt$
RewriteRule .* - [R=429,L]mod_security Integration
apache
SecRule REQUEST_HEADERS:User-Agent "@contains GPTBot" \
"id:1001,phase:1,block,msg:'AI Crawler Rate Limited',\
setvar:ip.ai_crawler_count=+1,expirevar:ip.ai_crawler_count=300"
SecRule IP:AI_CRAWLER_COUNT "@gt 10" \
"id:1002,phase:1,block,msg:'AI Crawler Blocked'"Monitoring and Optimization Workflows
Effective crawl budget management requires continuous monitoring and adjustment. Manual oversight isn’t scalable—you need automated systems that adapt to changing crawler behavior.
Automated Monitoring Setup
Key Performance Indicators Track these metrics daily:
- Total crawler requests by category (search engines vs. AI crawlers vs. unknown)
- Server resource consumption per crawler type
- Response time impact during high-crawl periods
- Crawl efficiency ratios (unique pages crawled vs. total requests)
Alert Thresholds Set up alerts for:
# Critical alerts
- Search engine crawler 4xx rate > 5%
- Total crawler traffic > 70% of server capacity
- Unknown crawler surge (300% increase day-over-day)
# Warning alerts
- AI crawler traffic > 40% of total crawler volume
- Crawl rate limiter blocking search engine crawlers
- New user agents accounting for >1% of trafficPerformance Impact Assessment
Resource Consumption Analysis Measure the actual impact of different crawler types on your infrastructure:
CPU Usage Correlation Monitor CPU utilization during peak crawler activity periods. Document which crawler types correlate with resource spikes.
Database Query Impact Track database connection pools and query execution times during heavy crawler periods. Some crawlers trigger expensive operations that others avoid.
CDN and Caching Efficiency Analyze cache hit rates for different crawler types. Poor cache performance from specific crawlers indicates inefficient crawling patterns.
Optimization Feedback Loops
Weekly Analysis Routine
- Review crawler traffic patterns and identify anomalies
- Analyze blocked vs. served requests by crawler category
- Correlate crawler activity with search performance metrics
- Adjust rate limits and blocking rules based on data
Monthly Strategic Review
- Assess overall crawl budget allocation effectiveness
- Review new crawler user agents and classification
- Update bot fingerprinting rules based on evolving patterns
- Benchmark server performance improvements from crawler management
Measuring Impact on Search Performance
The ultimate test of crawl budget optimization is whether it improves your search engine visibility and performance. Tracking these correlations requires sophisticated measurement approaches.
Search Performance Correlation Analysis
Crawl Efficiency Metrics Monitor how changes in crawler management affect search engine crawling behavior:
- Index Coverage Improvements: Track whether blocking AI crawlers leads to better indexing of important pages
- Crawl Freshness: Measure how quickly search engines discover and index new content after crawler optimizations
- Deep Page Discovery: Analyze whether improved crawl budget allocation leads to better indexing of deeper site pages
Technical SEO Health Indicators
- Core Web Vitals Impact: Measure whether reduced crawler load improves site performance metrics
- Server Response Time Consistency: Track whether crawler management reduces response time variability
- Error Rate Reduction: Monitor 5xx errors during peak crawler activity periods
Long-Term Performance Tracking
Organic Traffic Correlation While not directly causal, monitor organic traffic trends after implementing crawler controls:
- Category-Level Analysis: Track whether specific content categories benefit from improved crawl allocation
- Long-Tail Performance: Measure whether deep pages gain visibility after crawler optimization
- Mobile vs. Desktop Impact: Analyze whether crawler management affects mobile crawling differently
Ranking Stability Improvements Document whether sites with better crawl budget management show more stable rankings:
- Ranking Volatility Reduction: Track ranking fluctuations before and after crawler optimization
- New Content Ranking Speed: Measure how quickly new content achieves rankings after publication
Ready to take control of your crawl budget and protect your server resources from inefficient AI crawlers? Book a comprehensive crawl audit and let’s identify exactly which crawlers are consuming your resources and develop a customized management strategy for your specific situation.
Is a senior SEO expert with over a decade of experience dominating the digital marketing battlefield. Since 2023, I’ve been riding the AI wave. Since 2024, I have started to work with the SEO Bazooka Blog.
Leave a Reply